
Management Summary
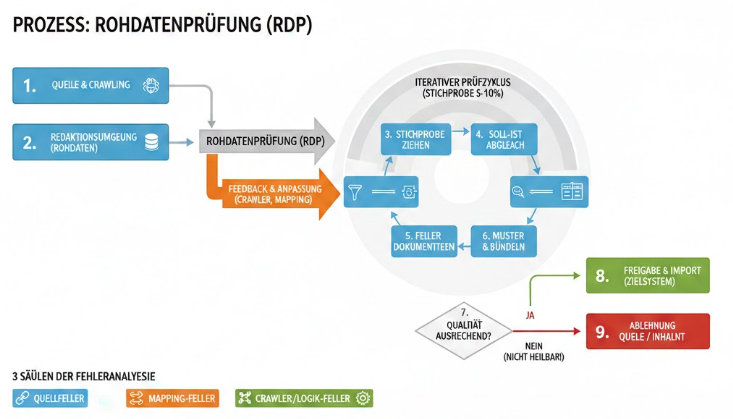
Die Rohdatenprüfung ist ein Teilprozess des Inhaltserschließungsprozesses und setzt ein, sobald Inhalte erstmalig durch einen Crawler in der Redaktionsumgebung verfügbar sind. Ziel ist es, durch stichprobenartige menschliche Prüfungen (ca. 5–10 % der Inhalte) Fehler im technischen Ablauf, in der Metadatengenerierung sowie im Mapping aufzudecken und als Feedback zur Optimierung zurückzugeben.
Dabei werden die im System vorhandenen Metadaten mit dem Originalinhalt der Quelle verglichen und auf Vollständigkeit, Korrektheit und Qualität geprüft. Zusätzlich werden technische und quellenbedingte Probleme (z. B. tote URLs) dokumentiert und – falls erforderlich – an die Quelle zurückgemeldet.
Die Dokumentation erfolgt strukturiert, idealerweise tabellarisch, mit Verlinkung zum Inhalt in der Redaktionsumgebung und zur Originalquelle sowie einer Beschreibung des Problems und einer vermuteten Ursache. Wiederkehrende Probleme werden gebündelt, um systematische Schwächen identifizieren zu können.
Die Rohdatenprüfung ist ein iterativer Prozess, der so lange wiederholt wird, bis die Qualität der Daten ausreichend ist oder eine Ablehnung aufgrund fehlender Korrekturmöglichkeiten erfolgt. Eine regelmäßige Durchführung auch bei Bestandsdaten wird empfohlen, um langfristige Qualitätsprobleme frühzeitig zu erkennen.
Einordnung im Gesamtprozess
Die Rohdatenprüfung ist ein Teilprozess des Inhaltserschließungsprozesses.
Sie setzt zu dem Zeitpunkt an, an dem Inhalte erstmalig durch einen Crawler im System bzw. in der Redaktionsumgebung verfügbar gemacht wurden.
Ziel der Rohdatenprüfung ist es, durch menschliche Nachprüfungen:
-
Fehler im technischen Ablauf (Crawler, Import, Mapping)
-
Fehler in der Erschließung und Metadatengenerierung
-
sowie Qualitätsprobleme in den Quelldaten
systematisch aufzudecken, zu dokumentieren und als Feedback zur Anpassung zurückzugeben.
Die Rohdatenprüfung ist ausdrücklich iterativ angelegt und wird so lange wiederholt, bis:
-
die Qualität als ausreichend bewertet wird oder
-
eine Ablehnung erfolgt, weil keine (oder keine wirtschaftlich sinnvollen) Korrekturmöglichkeiten bestehen.
Zielsetzung
Die Rohdatenprüfung verfolgt folgende Ziele:
-
Sicherstellung einer ausreichenden Daten- und Metadatenqualität
-
Frühes Erkennen systematischer Fehler im Erschließungsprozess
-
Verbesserung von:
-
Crawlern
-
Metadaten-Mapping
-
Filter- und Qualitätslogiken
-
-
Transparenz über Grenzen der Quelle (z. B. fehlende oder fehlerhafte Daten)
Umfang & Stichprobenstrategie
-
Es wird keine Vollprüfung durchgeführt.
-
Geprüft werden im Schnitt 5–10 % der Gesamtmenge einer Quelle.
-
Ziel ist eine möglichst breite Streuung, z. B.:
-
unterschiedliche Inhaltstypen
-
verschiedene Zeiträume
-
unterschiedliche Themen / Fachgebiete
-
-
Die Stichprobe dient der qualitativen Bewertung und nicht der Einzelfallkorrektur.
Prüfgegenstand
1. Vergleich mit dem Original
Für jedes geprüfte Objekt werden die im System vorliegenden Daten mit dem Originalinhalt der Quelle verglichen:
-
Sind alle relevanten Inhalte korrekt übernommen?
-
Entsprechen die generierten Metadaten dem Original?
-
Sind Inhalte verloren gegangen oder falsch interpretiert worden?
2. Prüfung des Metadaten-Mappings
Zusätzlich wird geprüft, ob:
-
Metadatenfelder korrekt gemappt sind
-
Werte richtig zugeordnet wurden
-
kontrollierte Vokabulare / Kategorien korrekt angewendet wurden
-
Pflichtfelder korrekt befüllt oder nachvollziehbar leer sind
3. Redaktioneller Handlungsbedarf
In der Redaktionsumgebung werden Inhalte u. a. anhand folgender Kriterien identifiziert:
Beispiele für redaktionellen Handlungsbedarf:
-
Objekte mit rechtlichen Problemen
-
Objekte mit fehlenden Pflichtdaten
-
Objekte mit defekten oder gelöschten Links
-
Objekte ohne Link
-
Private / ungeprüfte Objekte in Sammlungen
-
Objekte ohne:
-
Titel
-
Kategorie / Typ des Inhalts
-
Lizenz
-
Fach- / Sachgebiet
-
Herkunft des Inhalts / Bezugsquelle
-
Beschreibung
-
Bildungsstufe
-
Zielgruppe
-
Vorschaubild
-
Diese Kriterien dienen sowohl der Qualitätsbewertung als auch der Identifikation systematischer Schwächen.
4. Technische & quellenbedingte Fehler
Nicht alle Fehler entstehen im Erschließungsprozess selbst. Typische externe Probleme sind z. B.:
-
tote oder nicht mehr erreichbare URLs
-
veraltete oder inkonsistente Quelldaten
-
fehlende Metadaten bereits in der Quelle
Diese werden:
-
für die Qualitätsbewertung dokumentiert
-
bei Bedarf an die jeweilige Quelle zurückgemeldet
Dokumentation & Feedback
Alle im Rahmen der Rohdatenprüfung identifizierten Auffälligkeiten und Fehler werden strukturiert dokumentiert, um sie nachvollziehbar auszuwerten und gezielt anpassen zu können.
Strukturierte Dokumentation
Für die Dokumentation wird empfohlen, den Abgleich tabellarisch vorzunehmen, z. B. in Form einer Tabelle auf der jeweiligen Confluence-Unterseite einer Quelle.
Grundprinzip:
➡ Ein Objekt = eine Tabellenzeile
Empfohlene Spalten sind u. a.:
-
Link zum Inhalt in der Redaktionsumgebung
-
Link zur Originalquelle
-
Art des Problems
(z. B. fehlendes Metadatum, falsche Zuordnung, technischer Fehler) -
Kurzbeschreibung des Problems
-
Betroffenes Metadatenfeld / betroffene Felder
-
Vermutete Ursache, z. B.:
-
Quelle
-
Crawler
-
Metadaten-Mapping
-
Nachgelagerte Verarbeitung
-
-
Einschätzung der Relevanz (z. B. kritisch / mittel / gering)
-
Wiederholungsfall (ja / nein)
Diese Form ermöglicht:
-
einen schnellen Vergleich zwischen System und Original
-
eine konsistente Bewertung über mehrere Inhalte hinweg
-
eine einfache Weitergabe an technische oder fachliche Teams
Bündelung & Mustererkennung
Ein zentrales Ziel der Dokumentation ist nicht die Einzelfallkorrektur, sondern das Erkennen systematischer Probleme.
Daher gilt:
-
Wiederkehrende Probleme werden gebündelt
-
Häufigkeiten und Muster werden sichtbar gemacht
-
Einzelne Auffälligkeiten werden im Kontext der Gesamtstichprobe bewertet
Beispiele:
-
wiederholt fehlende Lizenzen → mögliches Mapping-Problem
-
wiederholt tote URLs → Problem in der Quelle
-
falsche Kategorien → unzureichende Zuordnung im Crawler
Nutzung des Feedbacks
Die dokumentierten Ergebnisse dienen als Grundlage für:
-
Anpassungen an:
-
Crawlern
-
Mapping-Regeln
-
Filtern und Qualitätslogiken
-
-
Rückmeldungen an Datenquellen
-
Entscheidungen über:
-
erneute Crawlläufe
-
Freigabe einer Quelle
-
Ablehnung bei fehlenden Korrekturmöglichkeiten
-
Iterativer Charakter
Die Rohdatenprüfung ist ein wiederkehrender Prozess:
-
Nach Anpassungen (z. B. am Crawler oder Mapping) erfolgt eine erneute Prüfung
-
Die Qualität wird schrittweise verbessert
-
Der Prozess endet erst bei:
-
ausreichender Qualität oder
-
bewusster Entscheidung gegen eine weitere Nutzung der Quelle
-
Rohdatenprüfung bei Bestandsdaten
Es wird empfohlen, die Rohdatenprüfung nicht nur bei neuen Quellen, sondern auch bei Bestandsdaten in regelmäßigen Abständen durchzuführen, um:
-
veränderte Qualitätsanforderungen abzubilden
-
neue technische Möglichkeiten zu nutzen
-
schleichende Qualitätsprobleme aufzudecken
-
Anpassungsbedarfe frühzeitig zu erkennen
Anlagen
Checkliste
1. Vorbereitung & Stichprobe
-
[ ] Stichprobenumfang definiert: Sind ca. 5–10 % der Gesamtmenge für die Prüfung ausgewählt?
-
[ ] Diversität sichergestellt: Deckt die Stichprobe unterschiedliche Inhaltstypen, Zeiträume und Fachgebiete ab?
-
[ ] Dokumentation bereit: Ist die Tabellenstruktur (z. B. in Confluence) für die Ergebnisse angelegt?
2. Abgleich mit der Originalquelle (Soll-Ist)
-
[ ] Vollständigkeit: Sind alle relevanten Textinhalte und Medien aus der Quelle im System angekommen?
-
[ ] Inhaltliche Korrektheit: Entspricht der Titel und die Beschreibung exakt dem Original?
-
[ ] Link-Check: Führt der URL-Link im System tatsächlich zum korrekten Originalinhalt?
-
[ ] Medien-Check: Werden Vorschaubilder oder eingebundene Medien korrekt angezeigt?
3. Metadaten-Mapping & Qualität
-
[ ] Pflichtfelder: Sind alle Pflichtfelder (Titel, Lizenz, Herkunft, Fachgebiet) befüllt?
-
[ ] Kategorisierung: Wurde der Inhalt dem korrekten Typ/Kategorie zugeordnet?
-
[ ] Vokabular-Check: Wurden kontrollierte Begriffe (z. B. Schlagworte) richtig angewendet?
-
[ ] Rechtliche Angaben: Ist die Lizenz korrekt vom Original übernommen oder gemappt worden?
-
[ ] Zielgruppen-Check: Sind Bildungsstufe oder Zielgruppe plausibel zugeordnet?
4. Technische Fehler & Quellprobleme
-
[ ] Erreichbarkeit: Sind die URLs der Quelle aktiv (keine 404-Fehler)?
-
[ ] Encoding/Darstellung: Werden Sonderzeichen und Umlaute korrekt dargestellt (kein Zeichensalat)?
-
[ ] Quell-Lücken: Falls Daten fehlen: Liegt es am Crawler oder fehlen sie bereits in der Quelle?
5. Dokumentation & Auswertung
-
[ ] Einzelfallerfassung: Ist jedes fehlerhafte Objekt mit Link zur Redaktionsumgebung und Originalquelle dokumentiert?
-
[ ] Ursachenvermutung: Wurde pro Fehler notiert, ob die Ursache bei der Quelle, dem Crawler oder dem Mapping liegt?
-
[ ] Mustererkennung: Wurden wiederkehrende Fehler gebündelt (z. B. "Fehlt bei allen PDF-Dateien")?
-
[ ] Relevanzbewertung: Sind die Fehler in kritisch, mittel oder gering priorisiert?
6. Abschluss & Feedbackschleife
-
[ ] Feedback-Übergabe: Wurden die gesammelten systematischen Fehler an das Technik-/Crawler-Team gemeldet?
-
[ ] Entscheidung getroffen: Ist die Qualität ausreichend für den Release oder ist eine weitere Iteration/Ablehnung nötig?